Building Scalable Applications: Microservice Architecture Challenges
While microservices architecture provides significant advantages in scalability, flexibility, and maintainability, it also introduces unique challenges that must be carefully considered when designing and implementing a robust and scalable application.
In this article, we will explore major challenges you may encounter in microservice architecture. Let's dive into these challenges and gain a deeper understanding of microservice architecture.
-
Challenge #1: How to define the boundaries of each microservice
One of the most significant challenges in microservices architecture is determining the boundaries of each service. Although the general guideline is for each service to handle "one thing," applying this principle requires thoughtful deliberation.
There is no automated method to achieve the "perfect" design. It requires a thorough understanding of your business domain, specific requirements, and architectural traits.
To establish the boundaries of a microservice:
- Each microservice should have a single responsibility, focusing on a specific business function.
- Each microservices should avoid excessive communication; if two services are frequently interacting, they may be better off as a single microservice.
- Each microservice should be small enough for an independent team to develop and manage.
- Each microservice should be independently deployable.
- Each microservices should be loosely coupled and capable of evolving independently.
- Microservices must not compromise data consistency or integrity.
-
Challenge #2: How to create queries that retrieve data from several microservices
Imagine a scenario where you're designing a screen for a mobile app. With a single database, you can easily retrieve the necessary data for that screen through a SQL query that performs a complex join across multiple tables. However, when dealing with multiple databases, each managed by a different microservice, querying these databases to form a SQL join becomes impossible.
So solution to this challenge is to use aggregation microservices. It is a specialized service that gathers data from various microservices, merges the results, and provides a consolidated response to the client.
Here are some popular aggregation microservices types.
-
API Gateway:
This pattern is a service that offers a single entry point for specific groups of microservices. It resembles the Facade pattern in object-oriented design but is implemented in a distributed system. You can use cloud API gateway Azure API Gateway, AWS API Gateway, Google GCP Gateway OR Ocelet API Gateway.
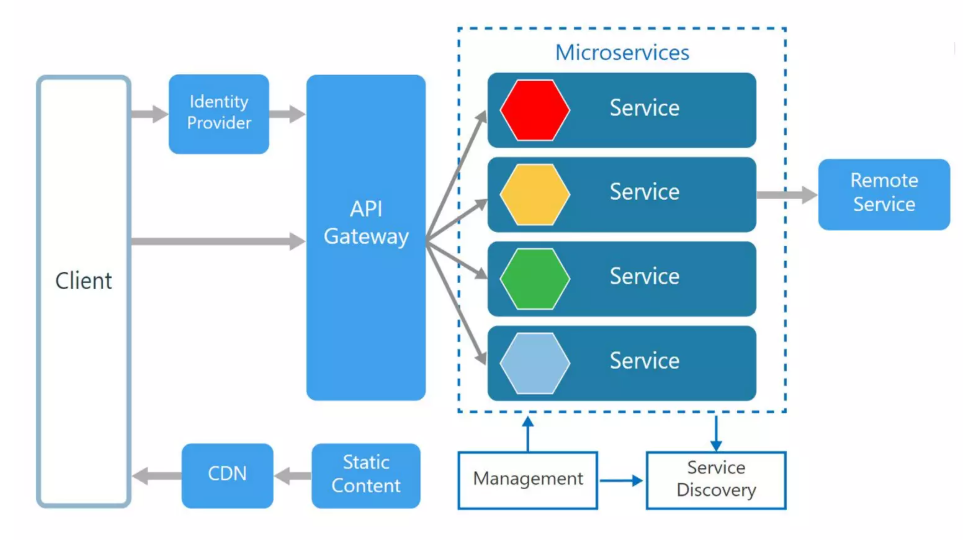
-
GraphQL Federation:
Federation enables you to create "subgraphs" from different services and combine them into a unified "supergraph," which functions as a complete, standalone schema. If you are already using GraphQL, then you can use Federation.
-
CQRS with query/reads tables:
You can meet the requirement by implementing a CQRS approach, where you create a denormalized table in a separate database solely for querying purposes. This table can be tailored to include only the data necessary for the complex query, with a one-to-one mapping between the fields required by your application’s interface and the columns in the query table.
-
“Cold data” in central database:
If real-time data is not critical for the client, such as for reporting purposes, you can export the transactional (hot) data to a separate centralized table or database, consolidating data from multiple databases owned by different microservices into cold storage.
-
-
Challenge #3: How to achieve consistency across multiple microservices
Each microservice owns private data that can only be accessed through its own API. This creates a challenge in implementing end-to-end business processes while maintaining consistency across multiple microservices.
Consider an eCommerce application with a product microservice, a cart microservice, and an order microservice.
The Product service is responsible for managing product data such as product ID, category, name, unit price, and current quantity.
The Cart service manages cart data, including customer details, product ID, quantity, and unit price.The Order service handles order placement. When an order is placed, the product's current quantity should be reduced. If the product's quantity reaches zero, carts containing that product should be notified.
In a monolithic architecture, a single relational database could store the data for Product, Cart, and Order, Order service could update product and cart information using ACID transactions.
However, in a microservices architecture, data is distributed across separate data stores, making ACID transactions across the databases of different microservices impractical.The Order microservice should not update product or cart data directly. Instead, it should rely on eventual consistency and asynchronous communication, such as integration events (message- or event-based communication).
-
Challenge #4: How to design communication across microservice boundaries
Communication in a microservice-based application is challenging because multiple artifacts, small services, servers, and hosts must collaborate to complete a single business process. Therefore, communication between microservices needs to be both efficient and reliable.
A microservice can use various protocols and communication styles to interact with other microservices. It's essential to choose the appropriate protocol and communication method to ensure the smooth execution of business functionality.
Imagine you have an Order microservice that makes synchronous HTTP calls to the Payment microservice for processing payments, the Product microservice for updating product quantities, and the Cart microservice for removing products from the cart.
This creates a chain of HTTP request/response interactions. If any of these requests fail or partially fail, the entire order functionality could be at risk.
Microservices communicate using different network protocols and messaging systems.
-
HTTP/HTTPS:
Microservices often communicate through RESTful APIs over HTTP or HTTPS protocols. Each microservice exposes endpoints that enable other services to request or modify data. This method is straightforward and widely used, making it a popular choice for many applications. -
Event Streaming:
Event streaming facilitates asynchronous communication, decoupling services and enabling them to respond to events independently. It is typically implemented using tools like Apache Kafka, Apache Pulsar, or AWS Kinesis. This approach enhances scalability, fault tolerance, and responsiveness within a distributed microservice architecture.
In the previous example, the Order microservice publishes order placement data, which can be subscribed to by the Product or Cart services to take the necessary actions.
-
Messaging Queues:
Messaging queues in microservices provide an asynchronous communication mechanism that enables different services to exchange messages. In this setup, messages are placed in a queue and held temporarily until the receiving microservice is ready to process them. This approach decouples services, allowing them to operate independently without needing to communicate directly or be available simultaneously.
Common messaging queue tools used in microservices include RabbitMQ, Apache ActiveMQ, Amazon SQS, and Kafka (when used in certain configurations).
-
RPC (Remote Procedure Calls):
In microservices gRPC is a communication protocol that allows one service to invoke a function or procedure in another service over a network, making it appear as if the call is happening locally. This enables services to exchange data and request specific operations remotely.
-
Blog Search

-
Building Scalable Applications: Microservice Architecture Challenges
-
The Paradigm Shift to Low-Code and No-Code Development in Software Engineering
-
How To Use AutoMapper in ASP.NET Core Web API
-
Generate Log using Serilog And Seq In ASP.NET Core MVC 6
-
How to Setup CORS Policies in ASP.NET Core Web API